👉 Exemples simples
- Rédiger la réponse à un e-mail client : tâche ouverte, contexte variable, langage naturel. Avantage à l'IA probabiliste.
- Calculer un montant de TVA : tâche fermée, bien définie, calcul arithmétique. Avantage à l'approche déterministe.
- Identifier des spams : tâche complexe, motif implicite. L'hybride est souvent la meilleure option.
Aucune de ces deux approches ne domine l'autre dans toutes les situations. Chacune excelle dans son domaine, et échoue hors de son périmètre. Voici quelques cas, volontairement simples pour comprendre, illustrant quelle approche est préférable selon la nature de la tâche :
👉 Exemple 1 : Répondre à un e-mail client
Tâche orverte, contexte variable, langage naturel. Ici, l'approche probabiliste (IA) est clairement avantagée. Un modèle de langage peut comprendre le contexte d'un message et générer une réponse formulée de manière humaine, adaptée au ton et au contenu de l'e-mail initial. Une IA entraînée sur d'innombrables correspondances sait par exemple proposer une réponse polie à un client mécontent en utilisant les formulations appropriées. Essayez de coder cela en déterministe : il faudrait prévoir toutes les tournures possibles, le vocabulaire, les tons (formel/informel) et les intentions du client – une tâche pratiquement infaisable manuellement. Un programme classique pourrait tout au plus insérer des champs dans une réponse type, sans réelle compréhension. Par contraste, un LLM s'adapte naturellement à des millions de situations linguistiques différentes. Limite toutefois : l'IA peut générer une réponse inexacte sur le fond (par exemple, une information erronée sur le produit si elle hallucine). C'est pourquoi, dans un contexte professionnel, il est souvent nécessaire qu'un humain relise ou valide la réponse générée. Bilan : pour la création de texte riche en nuances, l'IA probabiliste est imbattable en productivité, mais doit être supervisée pour garantir la justesse du contenu.
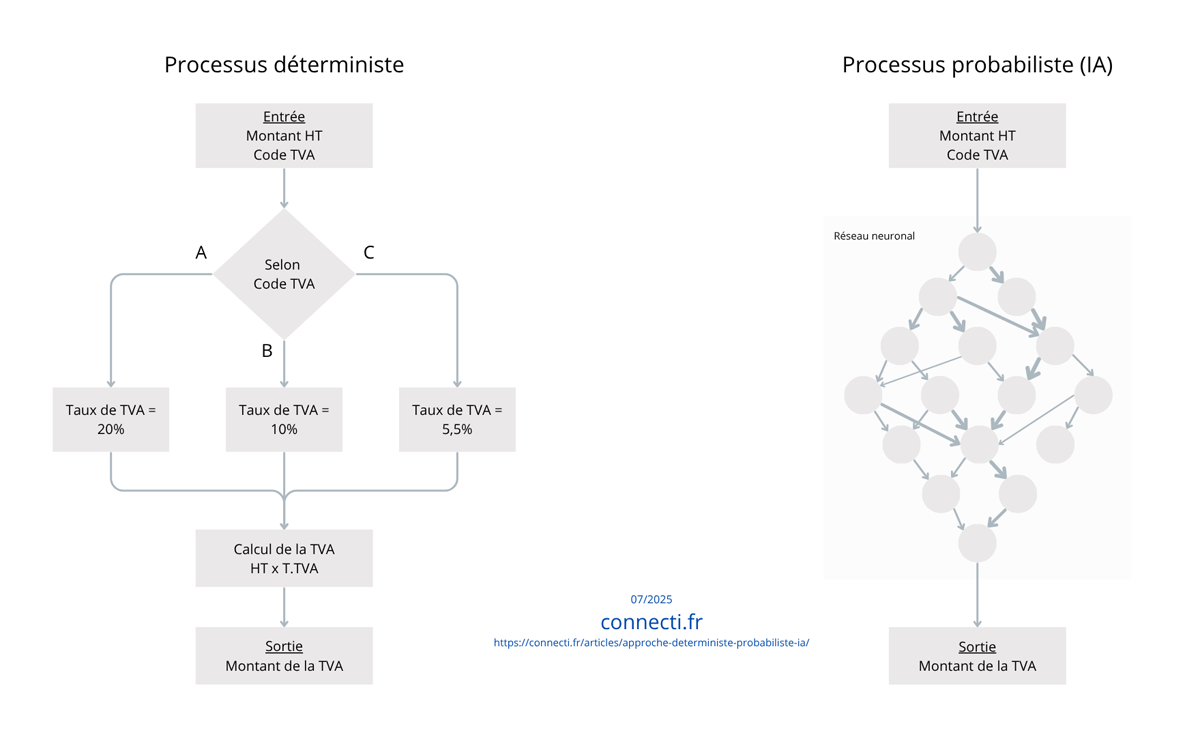
👉 Exemple 2 : Calculer la TVA à partir d'un HT et d'un code TVA
Tâche fermée, bien définie, calcul arithmétique. C'est le triomphe de l'approche déterministe. La règle de calcul est simple (par ex. « Prix TTC = Prix HT × taux TVA ») et ne souffre aucune exception : un code TVA correspond à un taux fixe. Un simple programme (ou même une formule Excel) suffit pour obtenir rapidement et avec une précision de 100% le résultat attendu. Demander à une IA généraliste de faire ce calcul serait non seulement inutilement complexe, mais peu sûr – elle pourrait se tromper si la formulation de la demande est ambiguë, se tromper sans raison ou donner un résultat sans expliquer le calcul. Avec un programme déterministe, on est certain du résultat tant que l'entrée est correcte. En bref : pour tout calcul réglementé et prévisible (taxes, conversions d'unités, calculs financiers standard…), mieux vaut une formule codée qu'un modèle probabiliste. Celui-ci n'apporterait aucune valeur ajoutée, et risquerait d'introduire de l'incertitude là où il ne devrait pas y en avoir.
👉 Exemple 3 : Détection de spams dans des e-mails
Tâche complexe, motif implicite. Initialement, les filtres anti-spam étaient basés sur des règles déterministes (par ex. « marquer comme spam tout message contenant tel mot-clé »). Cela fonctionne pour des cas simples, mais les expéditeurs de pourriels contournent vite ces règles (ils peuvent altérer les mots, utiliser des synonymes, etc.). Un système strictement déterministe devient alors une course sans fin pour ajouter sans cesse de nouvelles règles, avec un taux d'erreur qui monte (faux positifs ou messages indésirables non bloqués). Les filtres modernes utilisent donc massivement l'approche probabiliste : des algorithmes d'apprentissage automatique entraînés sur des millions d'e-mails sains vs spams apprennent à repérer des modèles beaucoup plus fins (choix de vocabulaire, fréquence de certains termes, structure du message, etc.). Résultat : un filtre bayésien ou à réseau de neurones détecte bien plus efficacement les spams, y compris ceux qu'aucune règle précise n'avait anticipés. Là encore toutefois, la perfection n'existe pas : un filtre probabiliste peut laisser passer un spam non identifié ou bloquer par erreur un courriel légitime. Une combinaison des deux approches peut donc être utile, par exemple en laissant quelques règles faciles en place (bloquer des expéditeurs déjà signalés comme nuisibles) tout en ayant le filtre statistique pour les cas plus subtils.
Synthèse
Les exemples ci-dessus illustrent des tâches simples, choisis pour bien faire comprendre les enjeux. Ils montrent clairement que, selon la situation, l'IA peut accomplir des prouesses là où le code classique atteint ses limites, tandis que dans d'autres cas, seul un programme déterministe garantit un résultat fiable. Les deux approches répondent à des logiques différentes et ne sont pas interchangeables en toute circonstance. Un système à règles offre une exactitude et un contrôle total sur un problème bien défini, tandis qu'un système apprenant apporte la souplesse et la puissance d'analyse indispensables pour traiter des problèmes plus complexes ou mal définis. Plutôt que d'opposer ces deux mondes, il est donc judicieux de chercher à en tirer le meilleur parti de façon combinée.
Et lorsque les tâches deviennent plus complexes, ces différences – et la nécessité de les associer intelligemment – ne font que s'amplifier.

